Progressive Web Apps in the HTTP Archive

By Thomas Steiner. Written on . Technical
Thomas Steiner, Google Hamburg, Germany
📧 tomac@google.com • 🐦 @tomayac • 😸 tomayac
Abstract
In this document, we present three different approaches and discuss their particular pros and cons for extracting data about Progressive Web Apps (PWA) from the HTTP Archive. Approach 1 is based on data that is tracked in the context of runs of the Lighthouse tool, Approach 2 is based on use counters in the Chrome browser to record per-page anonymous aggregated metrics on feature usage, and Approach 3 is based on parsing the source code of web pages for traces of service worker registrations and Web App Manifest references. We find that by all three approaches the popularity of PWAs increases roughly linearly over time and provide further research ideas based on the extracted data, whose underlying queries we share publicly.
Introduction to Progressive Web Apps
Progressive Web Apps (PWA) are a new class of web applications, enabled for the most part by the Service Worker APIs. Service workers allow apps to support network-independent loading by intercepting network requests to deliver programmatic or cached responses, service workers can receive push notifications and synchronize data in the background even when the corresponding app is not running, and service workers—together with Web App Manifestsallow users to install PWAs to their devices' home screens. Service workers were first implemented in Chrome 40 Beta released in December 2014, and the term Progressive Web Apps was coined by Frances Berriman and Alex Russell in 2015.
Research Questions and Problem Statement
As service workers are now finally implemented in all major browsers, we at the Google Web Developer Relations team were wondering how many PWAs are actually out there in the wild and how do they make use of these new technologies? Certain advanced APIs like Background Sync are currently still only available on Chromium-based browsers, so as an additional question we looked into what features do these PWAs actually use—or in the sense of progressive enhancement—try to use? Our first idea was to check some of the curated PWA catalogues, for example, PWA.rocks, PWA Directory, Outweb, or PWA Stats. The problem with such catalogues is that they suffer from what we call submission bias. Anecdotal evidence shows that authors of PWAs want to be included in as many catalogues as possible, but oftentimes the listed examples are not very representative of the web and rather longtail. For example, at the time of writing, the first listed PWA on PWA Directory is feuerwehr-eisolzried.de, a PWA on the "latest news, dates and more from [the] fire department in Eisolzried, Bavaria." Second, while PWA Stats offers tags, for example, on the use of notifications, not all PWA features are classified in their tagging system. In short, PWA catalogues are not very well suited for answering our research questions.
The HTTP Archive to the Rescue
The HTTP Archive tracks how the web is built and provides historical data to quantitatively illustrate how the web is evolving. The archive's crawlers process 500,000 URLs for both desktop and mobile twice a month. These URLs come from the most popular 500,000 sites in the Alexa Top 1,000,000 list and are mostly homepages that may or may not be representative for the rest of the site. The data in the HTTP Archive can be queried through BigQuery, where multiple tables are available in the httparchive project. As these tables tend to get fairly big, they are partitioned, but multiple associated tables can be queried using the wildcard symbol '*'. For our purposes, three families of tables are relevant, leading to three different approaches:
httparchive.lighthouse.*, which contains data about Lighthouse runs.httparchive.pages.*, which contain the JSON-encoded parent documents' HAR data.httparchive.response_bodies.*, which contains the raw response bodies of all resources and sub-resources of all sites in the archive.
In the following, we will discuss all three approaches and their particular pros and cons, as well as present the extractable data and ideas for further research. All queries are also available on GitHub and are released under the terms of the Apache 2.0 license.
⚠️ Warning: while BigQuery grants everyone a certain amount of free quota per month, on-demand pricing kicks in once the free quota is consumed. Currently, this is $5 per terabyte. Some of the shown queries process 70+(!) terabytes! You can see the amount of data that will be processed by clicking on the Validator icon:

Approach 1: httparchive.lighthouse.* Tables
Description
Lighthouse is an automated open-source tool for improving the quality of web pages. One can run it against any web page, public or requiring authentication. It has audits for Performance, Accessibility, Progressive Web App, and more. The httparchive.lighthouse.* tables contain JSON dumps (example) of past reports that can be extracted via BigQuery.
Cons
The biggest con is that obviously the tables only contain data of web pages that were ever run through the tool, so there is a blind spot. Additionally, while latest versions of Lighthouse process mobile and desktop pages, the currently used Lighthouse only processes mobile pages, so there are no results for desktop. One pitfall when working with these tables is that in a past version of Lighthouse Progressive Web App was the first category that was shown in the tool, however the order was flipped in the current version so that now Performance is first. In the query we need to take this corner case into account.
Pros
On the positive side, Lighthouse has clear scoring guidelines based on the Baseline PWA Checklist for each version of the tool (v2, v3), so by requiring a minimum Progressive Web App score of ≥75, we can, to some extent, determine what PWA features we want to have included, namely, we can require offline capabilities and make sure the app can be added to the home screen.
Query and Results
Running the query below and then selecting distinct PWA URLs returns 799 unique PWA results that are known to work offline and to be installable to the user's home screen.
#standardSQL CREATE TEMPORARY FUNCTION getPWAScore(report STRING) RETURNS FLOAT64 LANGUAGE js AS """ $=JSON.parse(report); return $.reportCategories.find(i => i.name === 'Progressive Web App').score; """; CREATE TABLE IF NOT EXISTS `progressive_web_apps.lighthouse_pwas` AS SELECT DISTINCT url AS pwa_url, IFNULL(rank, 1000000) AS rank, date, platform, CAST(ROUND(score) AS INT64) AS lighthouse_pwa_score FROM ( SELECT REGEXP_REPLACE(JSON_EXTRACT(report, "$.url"), """, "") AS url, getPWAScore(report) AS score, REGEXP_REPLACE(REGEXP_EXTRACT(_TABLE_SUFFIX, "\d{4}(?:_\d{2}){2}"), "_", "-") AS date, REGEXP_EXTRACT(_TABLE_SUFFIX, ".*_(\w+)$") AS platform FROM `httparchive.lighthouse.*` WHERE report IS NOT NULL AND JSON_EXTRACT(report, "$.audits.service-worker.score") = 'true' ) LEFT JOIN ( SELECT Alexa_rank AS rank, Alexa_domain AS domain FROM # Hard-coded due to https://github.com/HTTPArchive/bigquery/issues/42 `httparchive.urls.20170315` WHERE Alexa_rank IS NOT NULL AND Alexa_domain IS NOT NULL ) AS urls ON urls.domain = NET.REG_DOMAIN(url) WHERE # Lighthouse "Good" threshold score >= 75 GROUP BY url, date, score, platform, date, rank ORDER BY rank ASC, url, date DESC;
Research Ideas
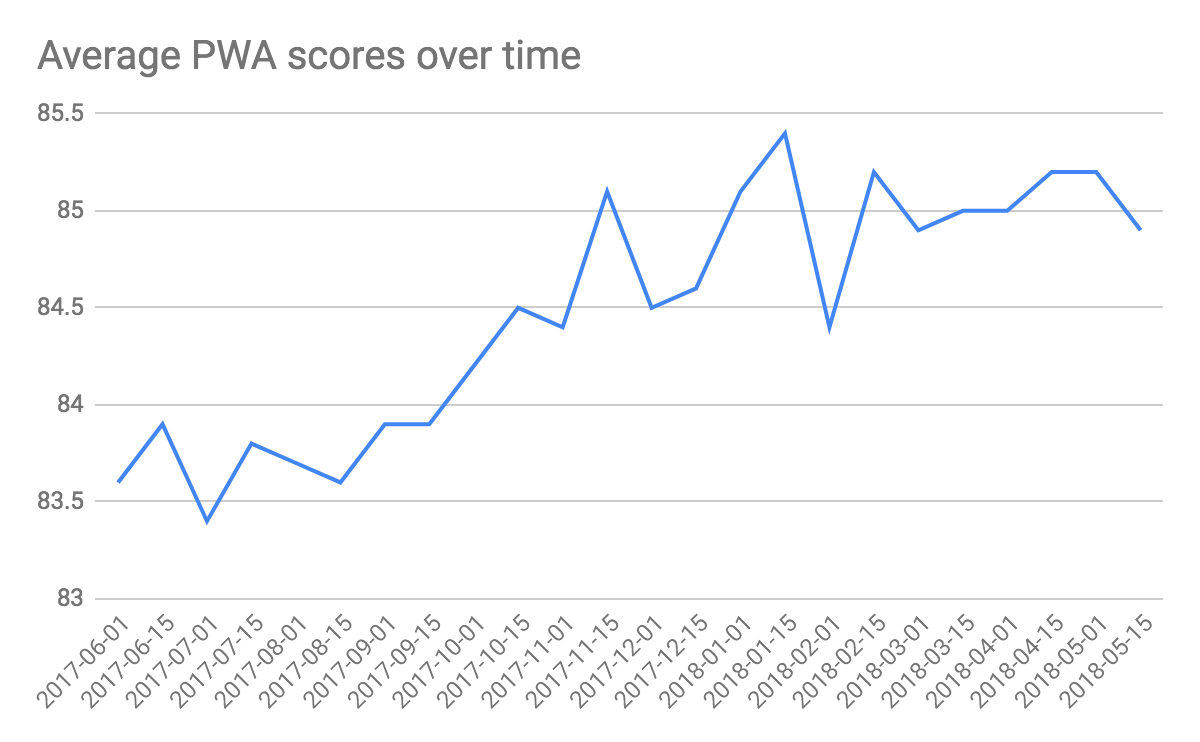
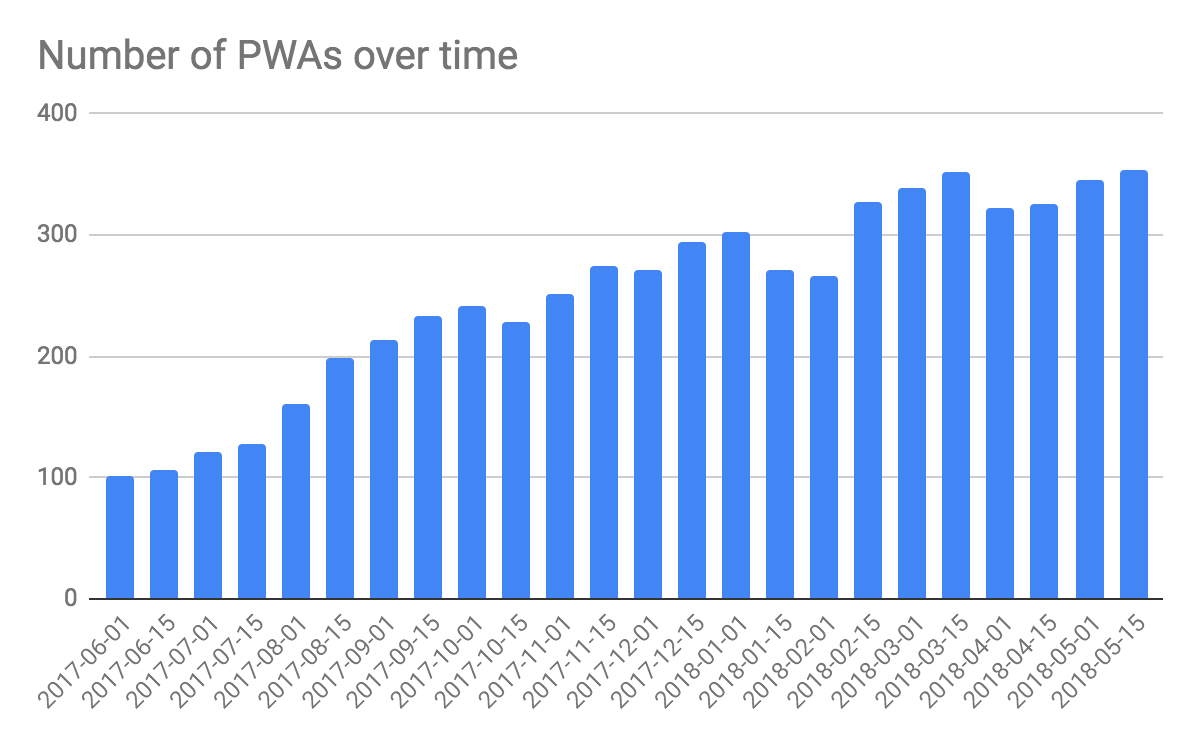
An interesting analysis we can run based on this data is the development of average Lighthouse PWA scores over time and the number of PWAs (note that the presented naive approach does not take the in relation also growing HTTP Archive into account, but purely counts absolute numbers).
#standardSQL SELECT date, count (DISTINCT pwa_url) AS total_pwas, round(AVG(lighthouse_pwa_score), 1) AS avg_lighthouse_pwa_score FROM `progressive_web_apps.lighthouse_pwas` GROUP BY date ORDER BY date;
Approach 2: httparchive.pages.* Tables
Description
Another straightforward way for estimating the amount of PWAs (however completely neglecting Web App Manifests) is to look for so-called use counters in the httparchive.pages.* tables. Particularly interesting is the ServiceWorkerControlledPage use counter, which, according to Chrome engineer Matt Falkenhagen, is counted whenever a page is controlled by a service worker, which typically happens only on subsequent loads.
Cons
No qualitative attributes other than the absolute fact that a service worker controlled the loading of the page can be extracted. More importantly, as the counter is typically triggered on subsequent loads only (and not on the first load that the crawler sees), this method undercounts and only contains sites that claim their clients (self.clients.claim()) on the first load.
Pros
On the bright side, the precision is high due to the browser-level tracking, so we can be sure the page actually registered a service worker. The query also covers both desktop and mobile.
Query and Results
This approach, at time of writing, turns up 5,368 unique results, however, as mentioned before, not all of these results necessarily qualify as PWA due to the potentially missing Web App Manifest that affects the installability of the app.
#standardSQL CREATE TABLE IF NOT EXISTS `progressive_web_apps.usecounters_pwas` AS SELECT DISTINCT REGEXP_REPLACE(url, "^http:", "https:") AS pwa_url, IFNULL(rank, 1000000) AS rank, date, platform FROM ( SELECT DISTINCT url, REGEXP_REPLACE(REGEXP_EXTRACT(_TABLE_SUFFIX, "\d{4}(?:_\d{2}){2}"), "_", "-") AS date, REGEXP_EXTRACT(_TABLE_SUFFIX, ".*_(\w+)$") AS platform FROM `httparchive.pages.*` WHERE # From https://cs.chromium.org/chromium/src/third_party/blink/public/mojom/web_feature/web_feature.mojom JSON_EXTRACT(payload, '$._blinkFeatureFirstUsed.Features.ServiceWorkerControlledPage') IS NOT NULL) LEFT JOIN ( SELECT Alexa_domain AS domain, Alexa_rank AS rank FROM # Hard-coded due to https://github.com/HTTPArchive/bigquery/issues/42 `httparchive.urls.20170315` AS urls WHERE Alexa_rank IS NOT NULL AND Alexa_domain IS NOT NULL ) ON domain = NET.REG_DOMAIN(url) ORDER BY rank ASC, date DESC, pwa_url;
Research Ideas
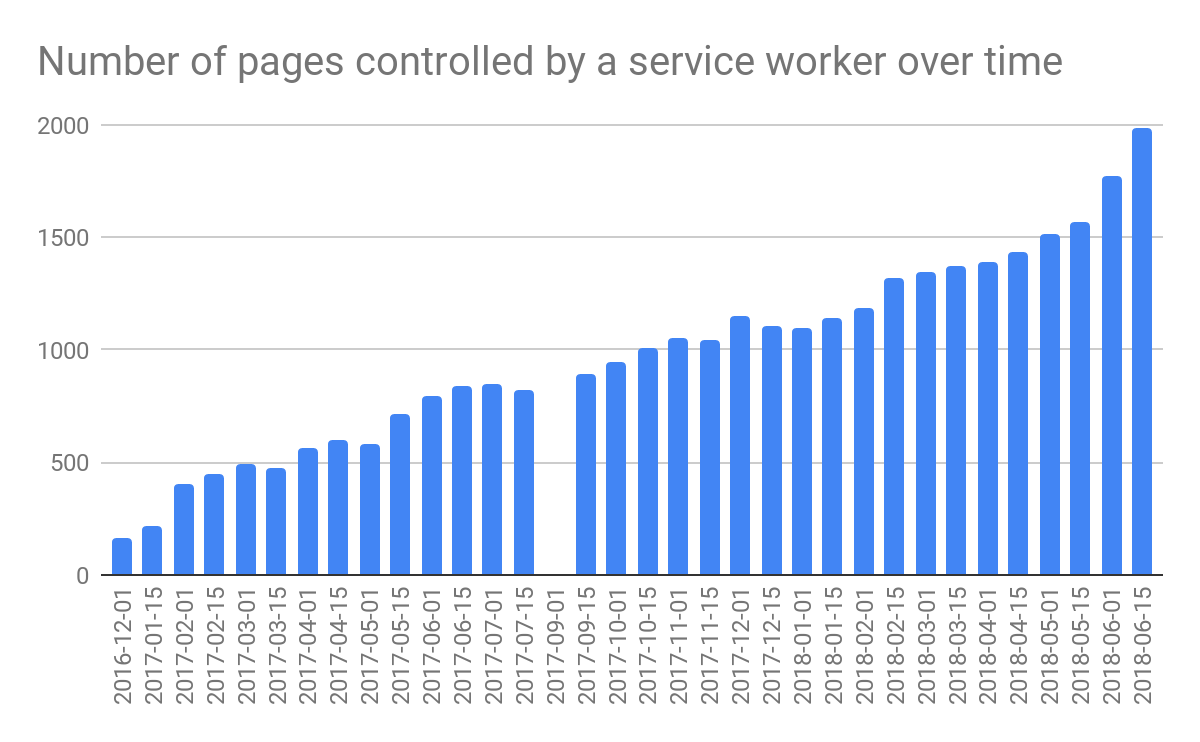
Similar to the second query in Approach 1 from above, we can also track the number of pages controlled by a service worker over time (the gap in the September 1, 2017 dataset is due to a parsing issue in the data collection pipeline).
#standardSQL SELECT date, count (DISTINCT pwa_url) AS total_pwas FROM `progressive_web_apps.usecounters_pwas` GROUP BY date ORDER BY date;
Approach 3: httparchive.response_body.* Tables
Description
A third less obvious way to answer our research questions is to look at actual response bodies. The httparchive.response_bodies.* tables contain raw data of all resources and sub-resources of all sites in the archive, so we can use fulltext search to find patterns that are indicators for the presence of PWA features like, for instance, the existence of variations of the string navigator.serviceWorker.register(" that provide a clue that the page might be registering a service worker on the one hand, and variations of <link rel="manifest" that point to a potential Web App Manifest on the other hand.
Cons
The downside of this approach is that we are trying to parse HTML with regular expressions to begin with, which is commonly known to be impossible and a bad practice. One example where things can go wrong is that we might detect out-commented code or struggle with incorrectly nested code.
Pros
Despite all challenges, as the service worker JavaScript files and the Web App Manifest JSON files are subresources of the page and therefore stored in the httparchive.response_bodies.* tables, we can still bravely attempt to examine their contents and try to gain an in-depth understanding of the PWAs' capabilities. By checking the service worker JavaScript code for the events the service worker listens to, we can see if a PWA—at least in theory—deals with Web Push notifications, handles fetches, etc., and by looking at the Web App Manifest JSON document, we can see if the PWA specifies a start URL, provides a name, and so on.
Query and Results
We have split the analysis of service workers and Web App Manifests, and use a common helper table to extract PWA candidates from the large response body tables. As references to service worker script files and Web App Manifest JSON files may be relative or absolute, we need a User-Defined Function to resolve paths like ../../manifest.json relative to their base URL. Our function is a hacky simplification based on path.resolve([...paths]) in Node.js and not very elegant. We deliberately ignore references that would require executing JavaScript, for example, URLs like window.location.href + 'sw.js', so our regular expressions are a bit involved to make sure we exclude these cases.
PWA Candidates Helper Table
#standardSQL CREATE TEMPORARY FUNCTION pathResolve(path1 STRING, path2 STRING) RETURNS STRING LANGUAGE js AS """ function normalizeStringPosix(e,t){for(var n="",r=-1,i=0,l=void 0,o=!1,h=0;h<=e.length;++h){if(h<e.length)l=e.charCodeAt(h);else{if(l===SLASH)break;l=SLASH}if(l===SLASH){if(r===h-1||1===i);else if(r!==h-1&&2===i){if(n.length<2||!o||n.charCodeAt(n.length-1)!==DOT||n.charCodeAt(n.length-2)!==DOT)if(n.length>2){for(var g=n.length-1,a=g;a>=0&&n.charCodeAt(a)!==SLASH;--a);if(a!==g){n=-1===a?"":n.slice(0,a),r=h,i=0,o=!1;continue}}else if(2===n.length||1===n.length){n="",r=h,i=0,o=!1;continue}t&&(n.length>0?n+="/..":n="..",o=!0)}else{var f=e.slice(r+1,h);n.length>0?n+="/"+f:n=f,o=!1}r=h,i=0}else l===DOT&&-1!==i?++i:i=-1}return n}function resolvePath(){for(var e=[],t=0;t<arguments.length;t++)e[t]=arguments[t];for(var n="",r=!1,i=void 0,l=e.length-1;l>=-1&&!r;l--){var o=void 0;l>=0?o=e[l]:(void 0===i&&(i=getCWD()),o=i),0!==o.length&&(n=o+"/"+n,r=o.charCodeAt(0)===SLASH)}return n=normalizeStringPosix(n,!r),r?"/"+n:n.length>0?n:"."}var SLASH=47,DOT=46,getCWD=function(){return""};if(/^https?:/.test(path2)){return path2;}if(/^\//.test(path2)){return path1+path2.substr(1);}return resolvePath(path1, path2).replace(/^(https?:\/)/, '$1/'); """; CREATE TABLE IF NOT EXISTS `progressive_web_apps.pwa_candidates` AS SELECT DISTINCT REGEXP_REPLACE(page, "^http:", "https:") AS pwa_url, IFNULL(rank, 1000000) AS rank, pathResolve(REGEXP_REPLACE(page, "^http:", "https:"), REGEXP_EXTRACT(body, "navigator\.serviceWorker\.register\s*\(\s*["']([^\),\s"']+)")) AS sw_url, pathResolve(REGEXP_REPLACE(page, "^http:", "https:"), REGEXP_EXTRACT(REGEXP_EXTRACT(body, "(<link[^>]+rel=["']?manifest["']?[^>]+>)"), "href=["']?([^\s"'>]+)["']?")) AS manifest_url FROM `httparchive.response_bodies.*` LEFT JOIN ( SELECT Alexa_domain AS domain, Alexa_rank AS rank FROM # Hard-coded due to https://github.com/HTTPArchive/bigquery/issues/42 `httparchive.urls.20170315` AS urls WHERE Alexa_rank IS NOT NULL AND Alexa_domain IS NOT NULL ) ON domain = NET.REG_DOMAIN(page) WHERE (REGEXP_EXTRACT(body, "navigator\.serviceWorker\.register\s*\(\s*["']([^\),\s"']+)") IS NOT NULL AND REGEXP_EXTRACT(body, "navigator\.serviceWorker\.register\s*\(\s*["']([^\),\s"']+)") != "/") AND (REGEXP_EXTRACT(REGEXP_EXTRACT(body, "(<link[^>]+rel=["']?manifest["']?[^>]+>)"), "href=["']?([^\s"'>]+)["']?") IS NOT NULL AND REGEXP_EXTRACT(REGEXP_EXTRACT(body, "(<link[^>]+rel=["']?manifest["']?[^>]+>)"), "href=["']?([^\s"'>]+)["']?") != "/") ORDER BY rank ASC, pwa_url;
Web App Manifests Analysis
Based on this helper table, we can then run the analysis of the Web App Manifests. We check for the existence of properties defined in the WebAppManifest dictionary combined with non-standard, but well-known properties like "gcm_sender_id" from the deprecated Google Cloud Messaging or "share_target" from the currently in flux Web Share Target API. Turns out, not many manifests are in the archive; from 2,823 candidate manifest URLs in the helper table we actually only find 30 unique Web App Manifests and thus PWAs in the response bodies, but these at least archived in several versions.
#standardSQL CREATE TABLE IF NOT EXISTS `progressive_web_apps.web_app_manifests` AS SELECT pwa_url, rank, manifest_url, date, platform, REGEXP_CONTAINS(manifest_code, r""dir"s*:") AS dir_property, REGEXP_CONTAINS(manifest_code, r""lang"s*:") AS lang_property, REGEXP_CONTAINS(manifest_code, r""name"s*:") AS name_property, REGEXP_CONTAINS(manifest_code, r""short_name"s*:") AS short_name_property, REGEXP_CONTAINS(manifest_code, r""description"s*:") AS description_property, REGEXP_CONTAINS(manifest_code, r""scope"s*:") AS scope_property, REGEXP_CONTAINS(manifest_code, r""icons"s*:") AS icons_property, REGEXP_CONTAINS(manifest_code, r""display"s*:") AS display_property, REGEXP_CONTAINS(manifest_code, r""orientation"s*:") AS orientation_property, REGEXP_CONTAINS(manifest_code, r""start_url"s*:") AS start_url_property, REGEXP_CONTAINS(manifest_code, r""serviceworker"s*:") AS serviceworker_property, REGEXP_CONTAINS(manifest_code, r""theme_color"s*:") AS theme_color_property, REGEXP_CONTAINS(manifest_code, r""related_applications"s*:") AS related_applications_property, REGEXP_CONTAINS(manifest_code, r""prefer_related_applications"s*:") AS prefer_related_applications_property, REGEXP_CONTAINS(manifest_code, r""background_color"s*:") AS background_color_property, REGEXP_CONTAINS(manifest_code, r""categories"s*:") AS categories_property, REGEXP_CONTAINS(manifest_code, r""screenshots"s*:") AS screenshots_property, REGEXP_CONTAINS(manifest_code, r""iarc_rating_id"s*:") AS iarc_rating_id_property, REGEXP_CONTAINS(manifest_code, r""gcm_sender_id"s*:") AS gcm_sender_id_property, REGEXP_CONTAINS(manifest_code, r""gcm_user_visible_only"s*:") AS gcm_user_visible_only_property, REGEXP_CONTAINS(manifest_code, r""share_target"s*:") AS share_target_property, REGEXP_CONTAINS(manifest_code, r""supports_share"s*:") AS supports_share_property FROM `progressive_web_apps.pwa_candidates` JOIN ( SELECT url, body AS manifest_code, REGEXP_REPLACE(REGEXP_EXTRACT(_TABLE_SUFFIX, "\d{4}(?:_\d{2}){2}"), "_", "-") AS date, REGEXP_EXTRACT(_TABLE_SUFFIX, ".*_(\w+)$") AS platform FROM `httparchive.response_bodies.*` WHERE body IS NOT NULL AND body != "" AND url IN ( SELECT DISTINCT manifest_url FROM `progressive_web_apps.pwa_candidates`) ) AS manifest_bodies ON manifest_bodies.url = manifest_url ORDER BY rank ASC, pwa_url, date DESC, platform, manifest_url;
Research Ideas
With this data at hand, we can extract all (well, not really all, but all known according to our query) PWAs that still use the deprecated Google Cloud Messaging service.
#standardSQL SELECT DISTINCT pwa_url, manifest_url FROM `progressive_web_apps.web_app_manifests` WHERE gcm_sender_id_property;
Service Workers Analysis
Similarly to the analysis of Web App Manifests, the analysis of the various ServiceWorkerGlobalScope events is based on regular expressions. Events can be listened to using two JavaScript syntaxes: (i) the property syntax (e.g., self.oninstall = […] or (ii) the event listener syntax (e.g., self.addEventListener('install', […])). As an additional data point, we extract potential uses of the increasingly popular library Workbox by looking for telling traces of various Workbox versions in the code. Running this query we obtain 1,151 unique service workers and thus PWAs.
#standardSQL CREATE TABLE IF NOT EXISTS `progressive_web_apps.service_workers` AS SELECT pwa_url, rank, sw_url, date, platform, REGEXP_CONTAINS(sw_code, r".oninstalls*=|addEventListener(s*["']install["']") AS install_event, REGEXP_CONTAINS(sw_code, r".onactivates*=|addEventListener(s*["']activate["']") AS activate_event, REGEXP_CONTAINS(sw_code, r".onfetchs*=|addEventListener(s*["']fetch["']") AS fetch_event, REGEXP_CONTAINS(sw_code, r".onpushs*=|addEventListener(s*["']push["']") AS push_event, REGEXP_CONTAINS(sw_code, r".onnotificationclicks*=|addEventListener(s*["']notificationclick["']") AS notificationclick_event, REGEXP_CONTAINS(sw_code, r".onnotificationcloses*=|addEventListener(s*["']notificationclose["']") AS notificationclose_event, REGEXP_CONTAINS(sw_code, r".onsyncs*=|addEventListener(s*["']sync["']") AS sync_event, REGEXP_CONTAINS(sw_code, r".oncanmakepayments*=|addEventListener(s*["']canmakepayment["']") AS canmakepayment_event, REGEXP_CONTAINS(sw_code, r".onpaymentrequests*=|addEventListener(s*["']paymentrequest["']") AS paymentrequest_event, REGEXP_CONTAINS(sw_code, r".onmessages*=|addEventListener(s*["']message["']") AS message_event, REGEXP_CONTAINS(sw_code, r".onmessageerrors*=|addEventListener(s*["']messageerror["']") AS messageerror_event, REGEXP_CONTAINS(sw_code, r"new Workbox|new workbox|workbox.precaching.|workbox.strategies.") AS uses_workboxjs FROM `progressive_web_apps.pwa_candidates` JOIN ( SELECT url, body AS sw_code, REGEXP_REPLACE(REGEXP_EXTRACT(_TABLE_SUFFIX, "\d{4}(?:_\d{2}){2}"), "_", "-") AS date, REGEXP_EXTRACT(_TABLE_SUFFIX, ".*_(\w+)$") AS platform FROM `httparchive.response_bodies.*` WHERE body IS NOT NULL AND body != "" AND url IN ( SELECT DISTINCT sw_url FROM `progressive_web_apps.pwa_candidates`) ) AS sw_bodies ON sw_bodies.url = sw_url ORDER BY rank ASC, pwa_url, date DESC, platform, sw_url;
Research Ideas
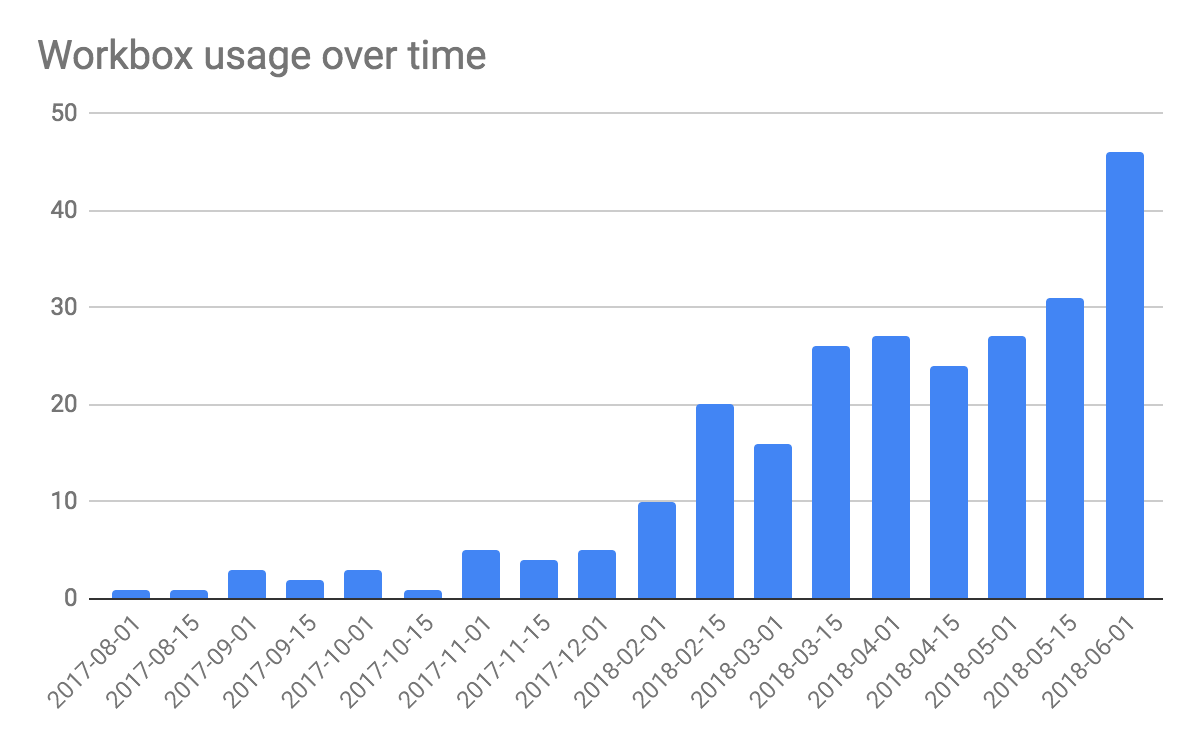
Having detailed service worker data allows for interesting analyses. For example, we can use this data to track Workbox usage over time.
#standardSQL SELECT date, count (uses_workboxjs) AS total_uses_workbox FROM `progressive_web_apps.service_workers` WHERE uses_workboxjs AND platform = 'mobile' GROUP BY date ORDER BY date;
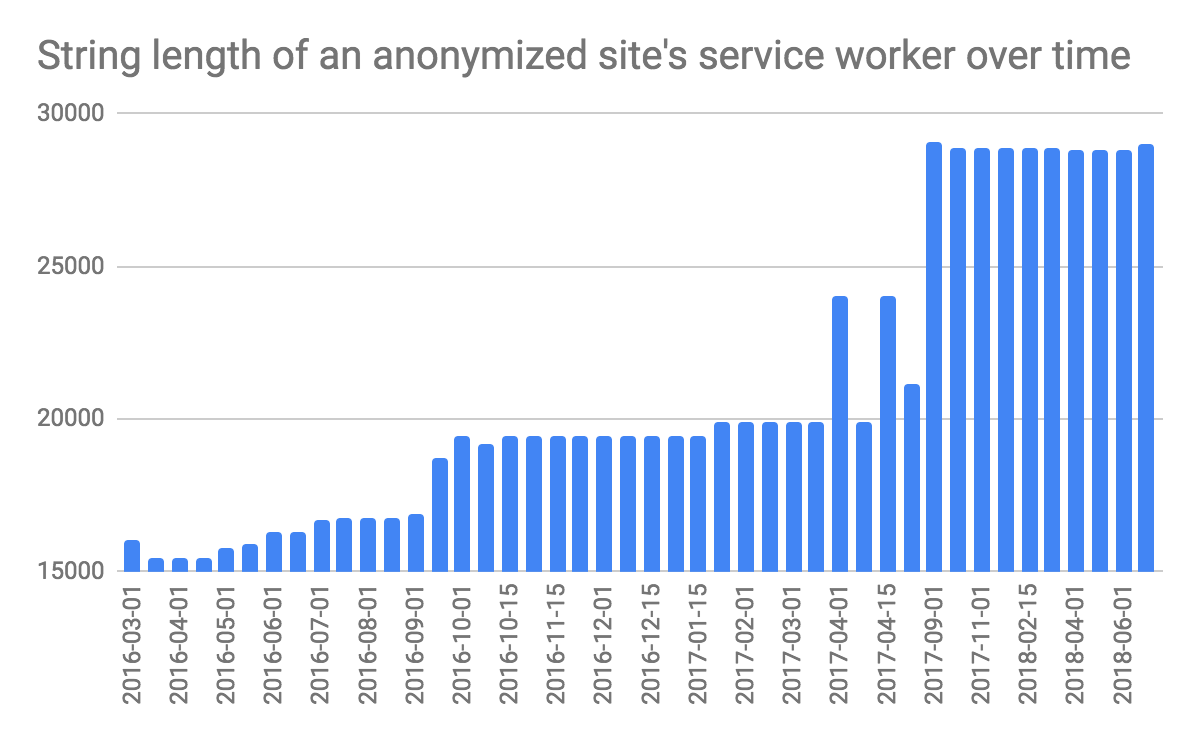
Lines of code (LOC) is a great metric (not) to estimate a team's productivity and to predict a task's complexity. Let's analyze the development of a given site's service worker in terms of string length. Seems like the team deserves a raise… 😉
#standardSQL SELECT DISTINCT pwa_url, sw_url, date, CHAR_LENGTH(body) AS sw_length FROM `progressive_web_apps.service_workers` JOIN `httparchive.response_bodies.*` ON sw_url = url AND date = REGEXP_REPLACE(REGEXP_EXTRACT(_TABLE_SUFFIX, "\d{4}(?:_\d{2}){2}"), "_", "-") AND platform = REGEXP_EXTRACT(_TABLE_SUFFIX, ".*_(\w+)$") WHERE # Redacted pwa_url = "https://example.com/" AND platform = "mobile" ORDER BY date ASC;
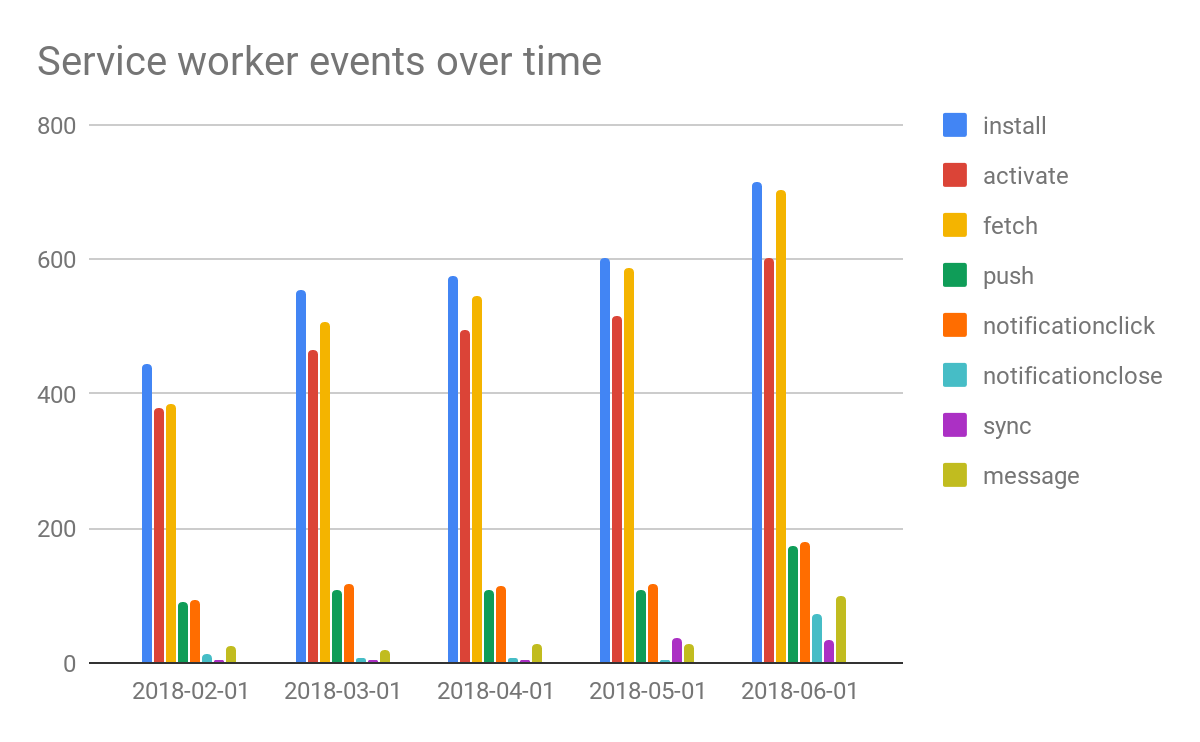
A final idea is to examine service worker events over time and see if there are interesting developments. Something that stands out in the analysis is how increasingly the fetch event is being listened to as well as the message event. Both are an indicator for more complex offline handling scenarios.
#standardSQL SELECT date, COUNT(IF (install_event, TRUE, NULL)) AS install_events, COUNT(IF ( activate_event, TRUE, NULL)) AS activate_events, COUNT(IF ( fetch_event, TRUE, NULL)) AS fetch_events, COUNT(IF ( push_event, TRUE, NULL)) AS push_events, COUNT(IF ( notificationclick_event, TRUE, NULL)) AS notificationclick_events, COUNT(IF ( notificationclose_event, TRUE, NULL)) AS notificationclose_events, COUNT(IF ( sync_event, TRUE, NULL)) AS sync_events, COUNT(IF ( canmakepayment_event, TRUE, NULL)) AS canmakepayment_events, COUNT(IF ( paymentrequest_event, TRUE, NULL)) AS paymentrequest_events, COUNT(IF ( message_event, TRUE, NULL)) AS message_events, COUNT(IF ( messageerror_event, TRUE, NULL)) AS messageerror_events FROM `progressive_web_apps.service_workers` WHERE NOT uses_workboxjs AND date LIKE "2018-%" GROUP BY date ORDER BY date;
Meta Approach: Approaches 13 Combined
An interesting meta analysis is to combine all approaches to get a feeling for the overall landscape of PWAs in the HTTP Archive (with all aforementioned pros and cons regarding precision and recall applied). If we run the query below, we find exactly 6,647 unique PWAs. They may not necessarily still be PWAs today; some of the previously very prominent PWA lighthouse cases are known to have regressed, and some were only very briefly experimenting with the technologies, but in the HTTP Archive we have evidence of the glory moment in history where all of these pages fulfilled at least one of our three approaches' criteria for being counted as a PWA.
#standardSQL SELECT DISTINCT pwa_url, rank FROM ( SELECT DISTINCT pwa_url, rank FROM `progressive_web_apps.lighthouse_pwas` union all SELECT DISTINCT pwa_url, rank FROM `progressive_web_apps.service_workers` union all SELECT DISTINCT pwa_url, rank FROM `progressive_web_apps.usecounters_pwas`) ORDER BY rank ASC;
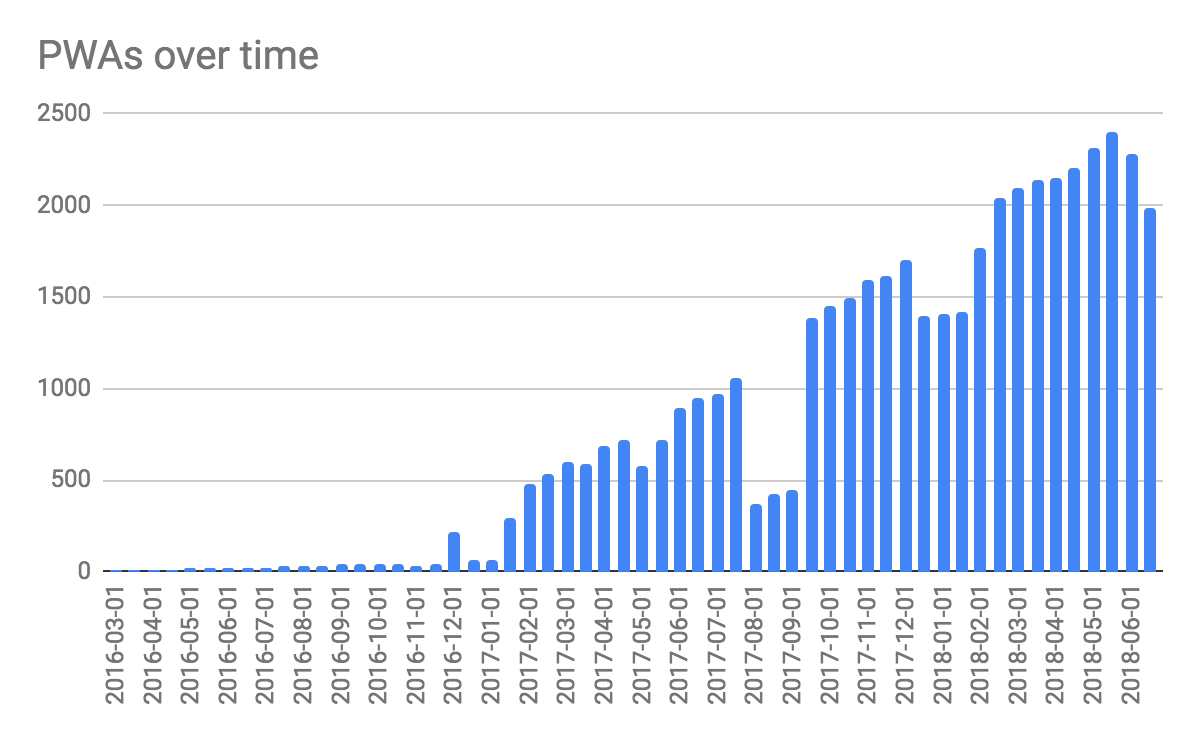
If we aggregate by dates and ignore some runaway values, we can see linear growth in the total number of PWAs, with a slight decline at the end of our observation period that we will have an eye on in future research.
#standardSQL SELECT DISTINCT date, COUNT(pwa_url) AS pwas FROM ( SELECT DISTINCT date, pwa_url FROM `progressive_web_apps.lighthouse_pwas` UNION ALL SELECT DISTINCT date, pwa_url FROM `progressive_web_apps.service_workers` UNION ALL SELECT DISTINCT date, pwa_url FROM `progressive_web_apps.usecounters_pwas`) GROUP BY date ORDER BY date;
Future Work and Conclusions
In this document, we have presented three different approaches to extracting PWA data from the HTTP Archive. Each has its individual pros and cons, but especially Approach 3 has proven very interesting as a basis for further analyses. All presented queries are evergreen in a sense that they are not tied to a particular crawl's tables, allowing for ongoing analyses also in the future. Depending on people's interest, we will see to what extent the data can be made generally available as part of the HTTP Archive's public tables. There are likewise interesting research opportunities by combining our results with the Chrome User Experience Report that is also accessible with BigQuery. Concluding, the overall trends show in the right direction. More and more pages are controlled by a service worker, leading to PWAs with a generally increasing Lighthouse PWA score. Something to watch out for is the decline in PWAs observed in the Meta Approach, which, however, is not reflected in the most precise and neutral Approach 2, where rather the opposite is the case. We look forward to learning about new ways people make use of our research and to PWAs becoming more and more mainstream.
Acknowledgements
In no particular order we would like to thank Mathias Bynens for help with shaping one of the initial queries, Kenji Baheux for pointers that led to Approach 2, Rick Viscomi and Patrick Meenan for general HTTP Archive help and the video series, Jeff Posnick, Ade Oshineye, Ilya Grigorik, John Mueller, Cheney Tsai, Miguel Carlos Martínez Díaz, and Eric Bidelman for editorial comments, as well as Matt Falkenhagen and Matt Giuca for providing technical background on use counters.